알고리즘
Correctness: 정답에 얼마나 근접한가
Presicion: 넣는 input이 달라져도 correctness는 같은가
Determinism: 같은 input을 넣으면 항상 같은 output이 나오는가
자료형
| boolean | 1 byte |
| char | 1 byte |
| short | 2 bytes |
| int | 4 bytes |
| float | 4 bytes |
| double | 8 bytes |
| pointer | 4 bytes or 8 bytes |
사용자 정의 자료형
struct: 다른 타입의 데이터를 하나로 묶기
union: 자료를 동시에 사용하지 않을 때 (가장 큰 자료형 만큼만 메모리 사용)
enum: 상수에 이름 붙인 거
빅오표기법
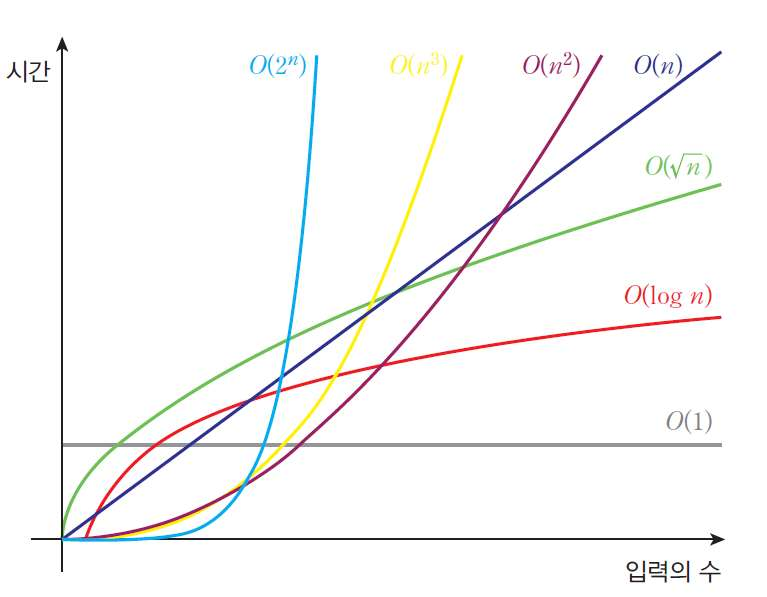
Divide Conquer(Recursive): 큰 문제를 쪼개서 해결, 쪼개진 문제는 독립된 문제로 여김 (여러개의 프로세서)
Dynamic Programming(Iterative): Logic이 항상 같음 (하나의 프로세서)
x^n 계산
반복적 방법1 - O(n)
double slow_power(double x, int n){
double result = 1.0;
for(int i = 0; i < n; i++) //그냥 x를 n번 Iterative하게 곱하기
result = result * x;
return result;
}순환적 방법 - O(logn)
double power(double x, int n){
if(n==0) return 1;
else if((n%2)==0) //n이 짝수면
return power(x*x, n/2) //recursive
else //n이 홀수면
return x*power(x*x, (n-1)/2); //recursive
}반복적 방법2 - O(logn)
exp_via_repeated_squaring(x,n){
result = 1;
a = x;
while(n > 0){
if(n mod 2 == 1) //이진수로 표현할 때 1인 경우에만 곱하기
result = result * a
a = a * a //x, x^2, x^4, x^8, x^16 ... 으로 변화
n = n/2의 내림
}
return result;
}피보나치
순환적 방법 - O(2^n)
int fib(int n){
if(n==0) return 0;
if(n==1) return 1;
return (fib(n-1)+fib(n-2)); //recursive
}
반복적 방법
int fib_iter(int n){
if(n==0) return 0;
if(n==1) return 1;
int pp = 0;
int p = 1;
int result = 0;
for(int i = 2; i <= n; i++){
result = p + pp; //f(n) = f(n-1) + f(n-2)
pp = p; //f(n-2)
p = result; //f(n-1)
}
return result;
}하노이 탑
f(n-1) * 2 + 1
//from에 쌓여있는 n개의 원판을 tmp를 사용하여 to로 옮기기
void hanoi_tower(int n, char from, char tmp, char to){
if(n==1) printf("원판을 %c에서 %c로 옮긴다", from, to);
else{
hanoi_tower(n-1, from, to, tmp); //n-1개를 from에서 tmp로 옮기기
printf("원판 %d을 %c에서 %c로 옮긴다", n, from, to); //가장 큰 원판 하나 옮기기
hanoi_tower(n-1, tmp, from, to); //n-1개를 tmp에서 to로 옮기기
}
}
Head recursion: fact(n) = fact(n-1) * n
Tail recursion: fact(n) = n * fact(n-1)
메모리 효용성 때문에 tail이 더 좋다(push 후에 바로 pop)
배열과 다항식
모든 항을 배열에 저장
#define MAX_DEGREE 101
typedef struct {
int degree;
float coef[MAX_DEGREE];
}polynomial;
polynomial a = { 5, {10, 0, 0, 0, 6, 3 } }; //차수 큰 것부터 저장polynomial poly_add1(polynomial A, polynomial B) {
polynomial C; //결과 다항식
int Apos = 0, Bpos = 0, Cpos = 0; //배열 인덱스
//지금 보고 있는 항 차수, 최대차항에서 출발
int degree_a = A.degree;
int degree_b = B.degree;
C.degree = MAX(A.degree, B.degree); //결과 다항식 차수
while (Apos < A.degree && Bpos < B.degree) {
if (degree_a > degree_b) { //A항 > B항
C.coef[Cpos++] = A.coef[Apos++];
degree_a--;
}
else if (degree_a == degree_b) { //A항 == B항
C.coef[Cpos++] = A.coef[Apos++] + B.coef[Bpos++];
degree_a--;
degree_b--;
}
else //B항 > A항
{
C.coef[Cpos++] = B.coef[Bpos++];
degree_b--;
}
}
return C;
}0이 아닌 항만 배열에 저장
#define MAX_TERMS 101
struct{
float coef;
int expon;
}terms[MAX_TERMS];
int avail;//C = A + B
//compare: 두 정수 비교하여 >,=,< 반환
//attach: avail 위치에 새로운 항 추가
poly_add2(int As, int Ae, int Bs, int Be, int *Cs, int *Ce){
float tempcoef;
*Cs = avail; //C를 저장할 시작 주소
while(As <= Ae && Bs <= Be){
switch(compare(terms[As].expon, terms[Bs].expon)){
case'>': //A의 차수 > B의 차수
attach(terms[As].coef, terms[As].expon);
As++;
break;
case'=': //A의 차수 == B의 차수
tempcoef = terms[As].coef + terms[Bs].coef;
if(tempcoef) attach(tempcoef, terms[As].expon); //0이 아닐 때
As++;
Bs++;
break;
case'<': //A의 차수 < B의 차수
attach(terms[Bs].coef, terms[Bs].expon);
Bs++;
break;
}
}
for(As <= Ae; As++){ //B가 먼저 끝나면 A의 나머지 항들을 이동
attach(terms[As].coef, terms[As]);
}
for(Bs <= Be; Bs++){ //A가 먼저 끝나면 B의 나머지 항들을 이동
attach(terms[Bs].coef, terms[Bs]);
}
*Ce = avail -1;
}희소행렬
대부분의 항들이 0인 배열
2차원 배열을 이용하여 배열의 전체 요소 저장
#define ROWS 3
#define COLS 3
void matrix_transpose(int A[ROWS][COLS], int B[ROWS][COLS]){
for(int r = 0; r < ROWS; r++)
for(int c = 0; c < COLS; c++)
B[c][r] = A[r][c];
}0이 아닌 요소들만 저장
typedef struct{
int row;
int col;
int value;
}element;
typedef struct SparseMatrix{
element data[MAX_TERMS];
int rows; //행의 개수
int cols; //열의 개수
int terms; //항의 개수
}SparseMatrix;SparseMatrix matrix_transpose2(SparseMatrix a){
SparseMatrix b;
int Bindex;
b.rows = a.cols;
b.cols = a.rows;
b.terms = a.terms;
if(a.terms > 0){
Bindex = 0;
//col기준으로 한 줄씩 term 있는지 확인하여 저장
for(int c = 0; c < a.cols; c++){
for(int i = 0; i < a.terms; i++){
if(a.data[i].col == c){
b.data[Bindex].row = a.data[i].col;
b.data[Bindex].col = a.data[i].row;
b.data[Bindex].value = a.data[i].value;
Bindex++;
}
}
}
}
return b;
}동적메모리 할당을 하면 heap에 저장됨
https://shinyunha.tistory.com/4
[자료구조] 스택
LIFO: Last-in First-out먼저 연산하고 싶은 것을 나중에 삽입스택 ADT(추상데이터타입)create(size)크기 size인 공백 스택 생성size(s)스택의 크기 리턴is_full(s)스택의 원소수가 size와 같으면 TRUEis_empty(s)스택
shinyunha.tistory.com
https://shinyunha.tistory.com/6
[자료구조] 큐
FIFO: First-In First-Out왼쪽 끝에서 삭제 오른쪽 끝에서 삽입 front: 가장 최근에 삭제된 데이터의 indexrear: 가장 최근에 삽입된 데이터의 index초기값은 둘 다 -1 모든 연산에 대한 시간 복잡도: O(1) 액션
shinyunha.tistory.com
https://shinyunha.tistory.com/m/12
[자료구조] 연결리스트
단순 연결리스트시간 복잡도O(n) 또는 O(1) 장점: 자투리 메모리 공간 사용 단점: 포인터 변수가 메모리를 차지함 배열에서 삽입연산을 하려면 다 뒤로 옮겨줘야함삭제연산을 하려면 다 앞으로 옮
shinyunha.tistory.com
https://shinyunha.tistory.com/13
[자료구조] 트리
계층적 자료구조 edge(간선): 노드와 노드 사이 연결node: 자료가 저장된 구조체 root node: 부모가 없는 최상위 조상 노드parent/child node: 하나의 간선으로 직접 연결된 상위/하위 계층 노드ancestor/descend
shinyunha.tistory.com
https://shinyunha.tistory.com/14
[자료구조] Heap
우선순위 큐저장순서에 상관없이 우선순위로 뽑아냄delete(q)우선순위가 가장 높은 요소 삭제find(q)우선순위가 가장 높은 요소 반환 최소 우선순위 큐(min heap): 값이 작은 노드가 우선순위가 높다
shinyunha.tistory.com
'자료구조' 카테고리의 다른 글
| [자료구조] 트리 (0) | 2025.10.27 |
|---|---|
| [자료구조] 연결리스트 (0) | 2025.10.26 |
| [자료구조] 큐 (0) | 2025.09.30 |
| [자료구조] 배열 - 다항식 더하기 (0) | 2025.09.27 |
| [자료구조] 스택 (0) | 2025.09.25 |